
Testing a Hive Patch on a Local System
- David McGinnis

- Mar 17, 2020
- 6 min read
Background
I was recently sent a reference to HIVE-21218, which is a Hive JIRA issue dealing with Hive's Kafka SerDe. The SerDe as of Hive 3.1 can read Avro-formatted data, as long as it is formatted according to the Apache Avro documentation.
The thing is, the Confluent platform's Avro serializer adds five bytes to the beginning of each Avro message. The first byte is a magic byte indicating this message is formatted per the Confluent parameters. The next four bytes are an integer pointer to the schema that the message follows in the Confluent Schema Registry associated with the serializer. You can read more about this format here.
Lots of times when I make changes to Apache projects, I find myself depending on unit tests to validate behavior. This is a bad idea in general, but more so since I was continuing on the work of an abandoned PR by someone else, which meant that I hadn't originally written the tests. That risk came to fruition when one of the reviewers found a very real bug in my code. Naturally, I immediately redid the tests so that this issue would be caught this time, but it was clear that we needed to try it in the wild as well.
To do this, though, I needed to get a Hive cluster running my code and a Confluent cluster that could output Avro messages in the proper format to test against. Given that I am not a company and don't have access to clusters like this already set up, I needed to create these locally to test against. Luckily, I had done some things similar to this before, so I had it partially finished already in a GitHub repo.
Enter HadoopOnVagrant
That GitHub repo is HadoopOnVagrant, which is publically accessible to anyone who might need these sorts of services. Vagrant is a technology that allows you to specify operations to do when starting up a generic virtual machine, based on one of many boxes they have pre-built for you. This means that you can specify shell scripts or Ansible workbooks to follow to make a repeatable process for creating virtual machines to do what you need them to. In our case, this allows us to make virtual machines that simulate environments that we need to test against.
The repo has a lot of different Vagrant files that allow for the creation of different environments, some of which even interoperate together. Some of these environments include:
FreeIPA Server
HDP 2.6.X and 3.X clusters
Linux Development Environments
If this sort of thing sounds useful to you, I encourage you to check it out and clone it! Feel free to file issues or send me PRs, as this is a resource I hope is useful to many people other than myself. It has certainly saved me a few times from myself already.
The one that was most interesting to me for the issue above was one I had built last year allowing you to run a generic version of Hive found in a tar-ball on a single node. At the time, I just needed the metastore, so I didn't install Hadoop on the node as well. Additionally, I didn't have any environments yet for Kafka or Confluent. That meant that I'd need to create one for Confluent.
Creating a Box for Confluent
The first step I wanted to follow was creating an environment to use Confluent in. I'll be honest that at the time I've never worked with Confluent directly, so it was a learning experience to be sure. Thankfully, they have a nice script that does most of the hard work for us, so in the end, the actual work of installing Confluent came down to the following code.
Confluent takes care of Zookeeper, Kafka, Kafka Connect, KSQL, and a nice web UI that you can manage everything from once everything is started.

Once I was able to access the UI well and everything looked to be working, I created a topic called avroTest that I was would use for my testing. Note that since I'm working with a single node cluster, I had to go into advanced settings, and make sure the replication rate was also set to 1. Otherwise, we would've gotten lots of errors when trying to get three replicas when we only have one broker.

With the topic created, I looked around the UI for a way to output some test data on this topic. Sadly, it seems either this isn't possible or the system isn't 100% healthy since I was unable to do so. Instead, I went ahead and used the command line, with the utility kafka-avro-console-producer, which produces Avro data into Kafka. This script is part of the Confluent platform and uses the Confluent serializer, so we knew it should work properly. As you can see in the screenshot below, it was fairly easy to do this through the console.

Once this was done and I had a few messages written, I could verify that it worked properly by looking in the UI itself.

Updating the Box for Hive
So next was getting Hive working. As I mentioned above, we already had a box, but it was only used to test the metastore, so it didn't have the Hadoop support that would be necessary to work with Hive.
The first step then was to take care of this. Thankfully, that was simple enough, since Hadoop doesn't really need an installation process itself, just get the binaries, unpack them, and set up a few environment variables so everyone knows where it is.
After this, I went ahead and started HDFS and YARN with the following script. I also went ahead and added a /user/hive/warehouse folder which Hive would need in order to store metadata in. Note that I'm running these commands as hdfs user, who is the superuser in the default settings.
Finally, with some trial and error, I found that I needed to have some settings added to the configuration files in order for HDFS, YARN, and Hive to all work properly.
First, in core-site.xml, I needed to add a defaultFS value, otherwise, it tried to use local, which wasn't going to work in our case.
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
I also needed to add a few configuration parameters to yarn-site.xml in order to ensure that the appropriate environment variables were available to YARN.
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
</value> </property> </configuration>
Finally, I added some configurations to mapred-site.xml, to ensure that it knew where the libraries were and that we were using YARN.
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value>
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
</value> </property> </configuration>
Starting Hive
After doing all this, I started Hive with the following command. Note we are using screen here so that we can have the service run in the background, even if we exit the shell. We can then come back to see the output of the service anytime we want. This is a really useful tool that isn't as well known as it should be, in my opinion.
After doing this, I used Beeline to connect directly to the HiveServer2 instance that the above command started. Here, I was able to create a table, but couldn't select from it. Instead, it came back with a permissions error. Instead of digging into this more, I opted to disable DoAs, which is a setting that determines whether HDFS operations are done as the hive user or as the original user. It was originally using the original user, which is, in theory, more secure, but for efficiency's sake, I moved it to be true so that it would use the hive user, which I knew was already working properly. This was done by setting the following in hive-site.xml.
<configuration> <property> <name>hive.server2.enable.doAs</name> <value>false</value> </property> </configuration>
After this, I was able to start Beeline and create the table that was based on the Kafka topic I had created earlier. After creating this table and selecting everything from it, we saw success, with all of the data being faithfully returned to us.
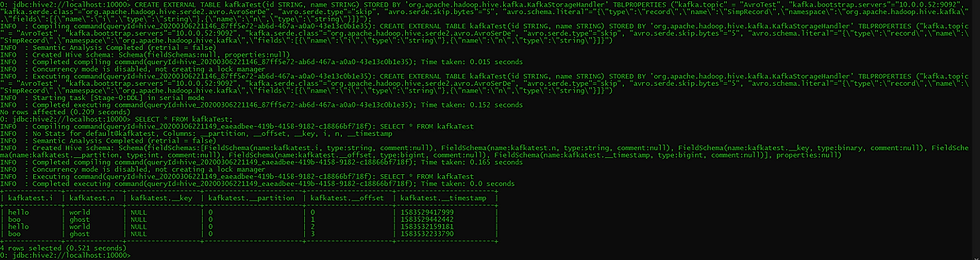
Conclusion
At long last, we were able to verify that my changes worked correctly, and we could now read data that was serialized by the Confluent Avro serializer in Hive through the Kafka SerDe!
After doing this, I was able to get a patch that fixed HIVE-21218 and passed the necessary tests. The patch was merged into master, and the fix will be available for Hive 4!
This was obviously a lot of work to do, but by doing all of this through Vagrant, we made this process repeatable. Additionally, not only will I be able to create a test system in the future of these components, but I'll be able to create any of them individually, or them working with other components such as Apache Kafka or a separate HDP cluster. Moreso, now with it being on GitHub, anyone who has a need for this can do the same thing. That's the power of Vagrant and the reason why doing the extra work to use Vagrant here makes sense.
Finally, I want to point out the learning experiences available here of how the actual Apache projects work themselves. Distributions like HDP and CDH hide alot of the complexity when dealing with Hadoop and Hive, even down to things as simple as creating a /tmp folder or setting some basic configuration parameters. These sorts of exercises help you better understand how the system actually works, making you a better administrator, even when working on the more polished distributions of Hadoop.



Comments